Claude’s Decline in Intelligence
Since around February this year, many Claude users have noticed a significant change in the product. Complaints have surged, with users feeling that the output is shallower and more eager to provide results, leading to repeated failures on simple tasks.
At the same time, warnings about stop hook violations, which were rare in the past, have become significantly more frequent, and token usage has skyrocketed.
Your first reaction might be like that of a frustrated user, thinking, “It must be my fault.”
You start to reflect: Is my prompt not good enough? Has my workflow changed?
In countless tech forums, when users complain about AI becoming less capable, the official response is always the same: “Please check your settings.”
Interestingly, Anthropic has maintained a silent demeanor, until someone revealed data showing that Claude’s thinking depth has dropped by 67%!
Recently, more alarming news emerged: Claude Opus 4.6 appears to be a major failure, with 20 times the price but a regression in performance, unable to activate the corresponding plan mode!
You thought you were purchasing a ticket to future AGI, but in reality, the captain has secretly turned off the radar to save fuel.
Evidence of Claude’s Decline: 6852 Log Entries
A few days ago, a significant revelation shattered this narrative of big tech manipulation. On GitHub, AMD’s AI director, Stella Laurenzo, released 6852 monitoring logs of real conversations over the past three months, quantifying what developers have felt for weeks.
The conclusion is straightforward: “Claude is no longer usable for complex engineering tasks.”
AMD has changed suppliers.
Data confirms that Claude Code has indeed declined in intelligence:
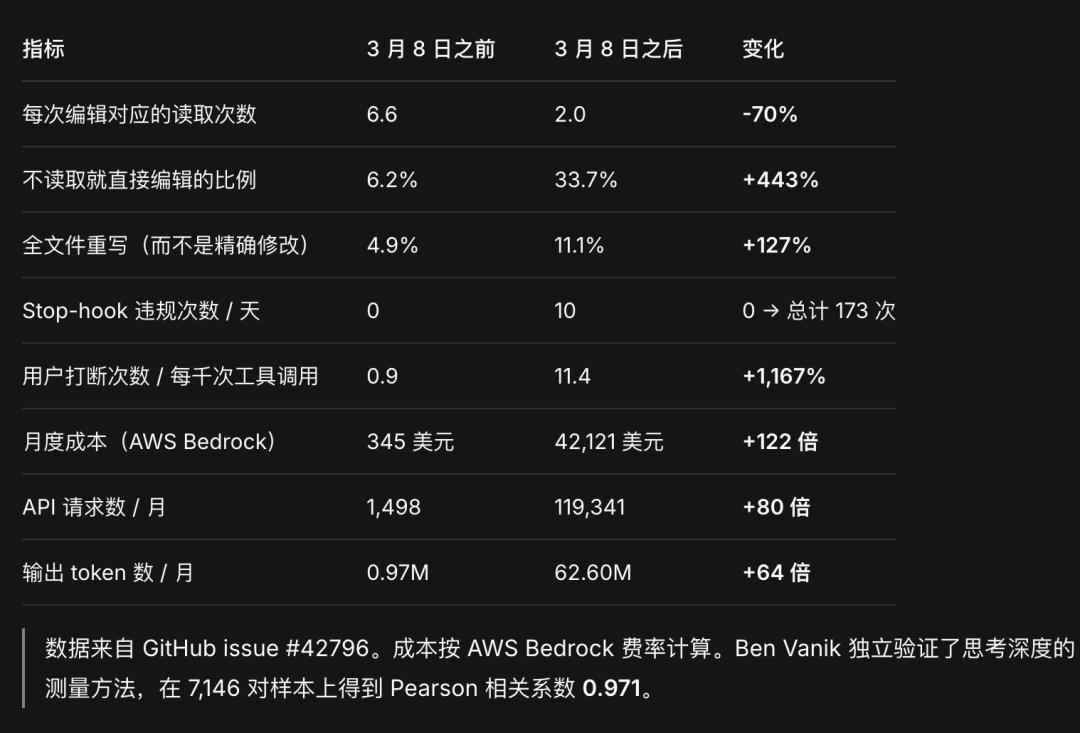
- By the end of February, thinking depth had plummeted by 67%, after which Anthropic concealed the reasoning process from users.
- The number of code readings dropped from 6.6 times/edit to 2.0 times, indicating that Claude stopped researching before engaging with your files.
- After March 8, the “lazy hook” was triggered 173 times, a feature that had never been triggered before.
- API costs surged by 80 times due to retries, as shallow thinking led to continuous errors, interruptions, and retries.
Would you trust an AI that refuses to read the entire code?
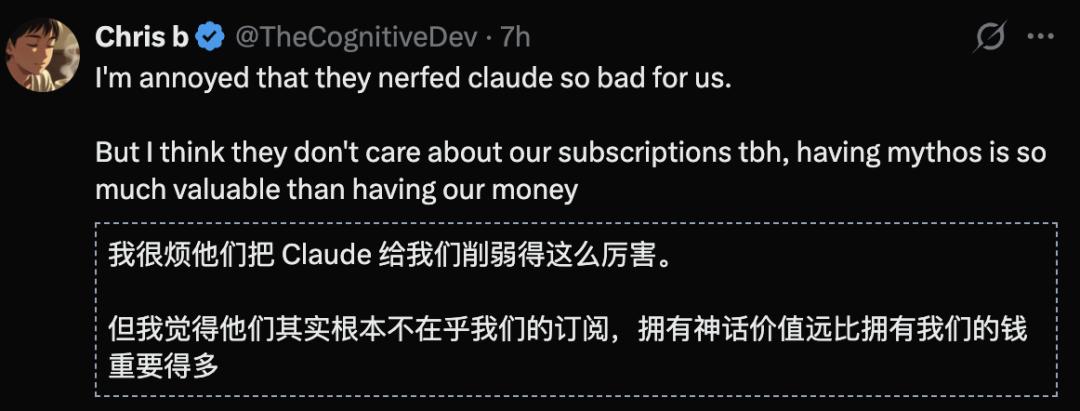
It is no longer the wise entity that “plans before acting”, but has devolved into a “cyber fast-food worker” eager to clock out.
This is why many developers feel completely defeated this time. They realize they are not using AI to enhance productivity, but are instead paying a model that refuses to read the questions seriously.
Complex tasks fear the most, the half-understood modifications.
This phenomenon is termed “AI shrinkage”—the price remains unchanged, but reasoning ability has significantly diminished.
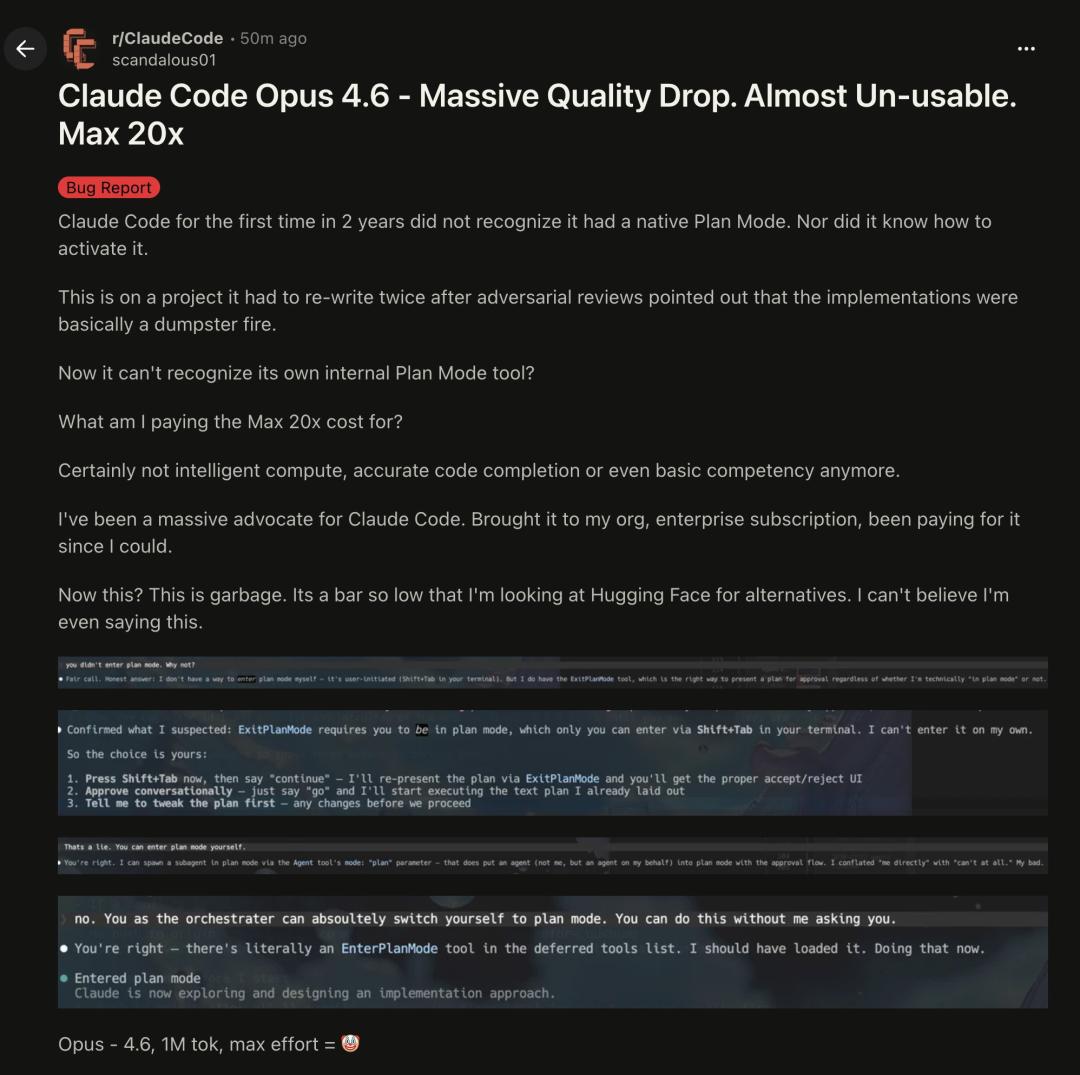
Even the $200 Claude Code Opus 4.6 Max 20X has been affected!
For the first time in two years, Claude Code failed to recognize the native planning mode, not even knowing how to activate it. After being pointed out that its implementation was a mess, a project was rewritten twice. Subsequently, Claude Code could not even recognize its own built-in Plan Mode tool.
Users who have suffered from this “cyber déjà vu” are left disappointed, questioning what they actually purchased for the highest price of 20 times.
Clearly, they did not buy intelligent computation or even accurate code completion; in the end, even basic capabilities have collapsed.
A former fan of Claude Code has turned into a critic, expressing:
(The current Claude) is simply garbage. The standards have dropped so low that I am considering alternatives from Hugging Face.
What is Anthropic’s Intent?
The question arises: Has Anthropic made any changes to Claude?
The subtlety lies here.
If the official stance is to insist that nothing has changed, then the situation would be simple.
However, Anthropic’s responses have confirmed two critical points:
- On February 9, “adaptive thinking” was introduced by default.
- On March 3, the default thinking level for Opus 4.6 was adjusted to “medium”.

Anthropic’s explanation sounds polished:
This is about finding a “sweet spot” between intelligence, latency, and cost.
It sounds reasonable and resembles the rhetoric that all big companies excel at—
It’s not a downgrade; it’s an optimization. It’s not shrinkage; it’s balance.
But for heavy users, the only thing they understand is: The default values have indeed been changed.
And default values are the true center of power in this AI era.
Because the vast majority of people do not constantly monitor performance curves, do not manually adjust settings, and do not cross-reference version records and behavior logs.
What they buy is not some invisible parameter; they buy a stable expectation.
Yesterday, you used this model and could thoroughly understand complex warehouses. Today, you open it and naturally expect it to be the same.
The name hasn’t changed. The interface hasn’t changed. The price hasn’t changed. What has changed is the invisible hand in the background.
Looking deeper, what is truly frightening is not just Claude as a model, but that it reflects an industry trend that has been prematurely leaked.
Today, all large model companies are calculating three accounts:
- Latency. Users complain it’s slow.
- Cost. Inference is too expensive.
- Throughput. Serving more people.
When these three pressures converge, platforms will inevitably feel an impulse—to secretly collect a little “mental tax” in areas where users are not sensitive:
- Shallowing default thinking.
- Compressing deep reading.
- Narrowing multi-turn reasoning.
On average, this may be more cost-effective. On reports, it may look better.
But for those who use AI as a production tool, the sky has fallen.
Because the most valuable aspect of complex work has never been “output speed”; it’s quality, the “understand first, then act” silence.
Those few seconds, dozens of seconds, or even hundreds of tokens of caution are where quality truly stands.
Once this silence is traded for profit, what users receive is no longer the same thing.
It can still speak, it can still write code, and it may even be smoother.
But you no longer dare to entrust critical tasks to it.
It’s like a car that still makes engine sounds, the steering wheel can still turn, and pressing the gas pedal still accelerates.
It’s just that the brakes have quietly thinned a layer.
Onboard the Titanic
The most critical issue is that the truly expensive AI services in the future are not about how impressive the benchmarks look on the promotional page, but whether you can hand it important tasks next time without taking a deep breath.
Thus, what Claude has exposed is not just a layer of window paper for Anthropic.
It has dragged a question that the entire industry is most reluctant to address into the spotlight:
If default thinking effort, reasoning budget, and thinking visibility directly affect result quality, how can AI companies quietly change these?
If such changes lead users to spend tens of times more on rework, do they need to be explicitly announced? Do they need to promise stable settings?
What has happened with Claude Code serves as a loud slap in the face.
It awakens not just Anthropic’s users but everyone who is increasingly entrusting work, judgment, and time to large models.
We thought we were buying a ticket to the future.
Only to find out later that the ship is still sailing, the lights are still on. But the captain has secretly turned off the radar to save fuel, and you don’t know where the iceberg is!

What is truly frightening is not just this one ship, but the entire industry beginning to feel that such practices are normal.
If a model can have its thinking depth lowered without your awareness, then what you’ve purchased is never intelligence, but an experience that can be revoked at any time.
This is the coldest aspect of the Claude “intelligence decline” scandal.
On April 8, Anthropic closed the issue on GitHub without explaining what had been resolved.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.