
Anthropic has announced the full release of its latest foundational model, Claude Opus 4.7, on Thursday evening.
Opus 4.7 shows significant improvements in advanced software engineering compared to Opus 4.6, especially in handling complex tasks. Users report that they can now confidently delegate previously closely monitored coding tasks to Opus 4.7. The model can rigorously and consistently manage complex, time-consuming tasks, execute instructions accurately, and design methods to validate its outputs before returning results.
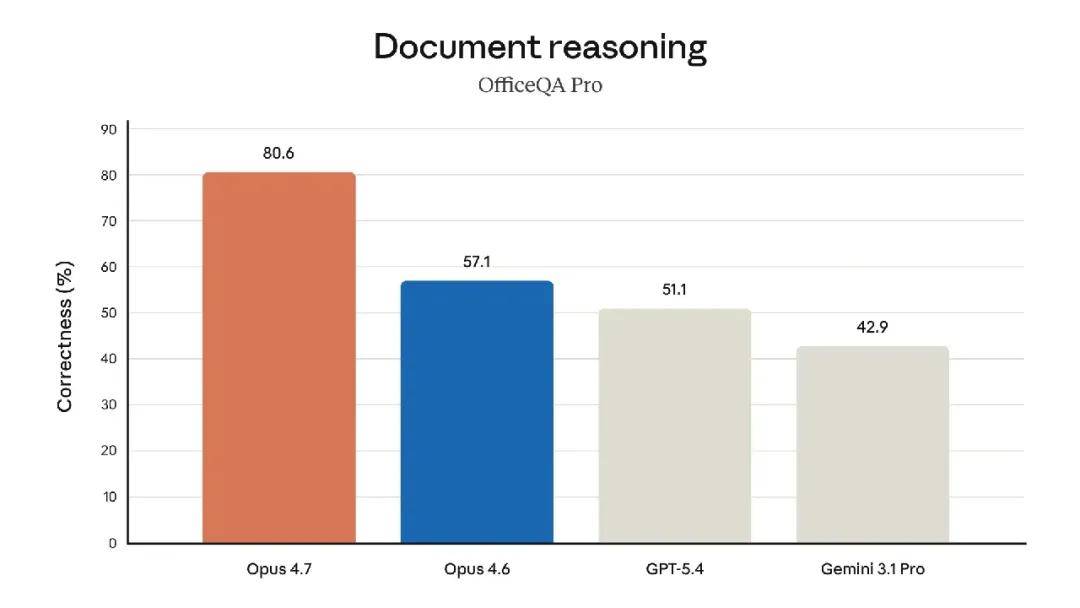
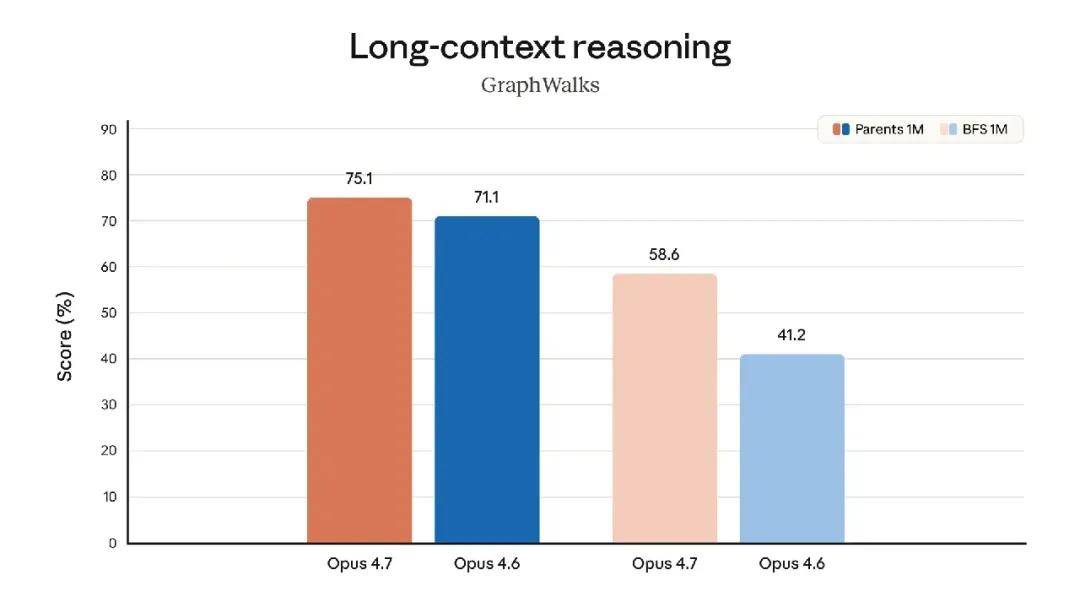
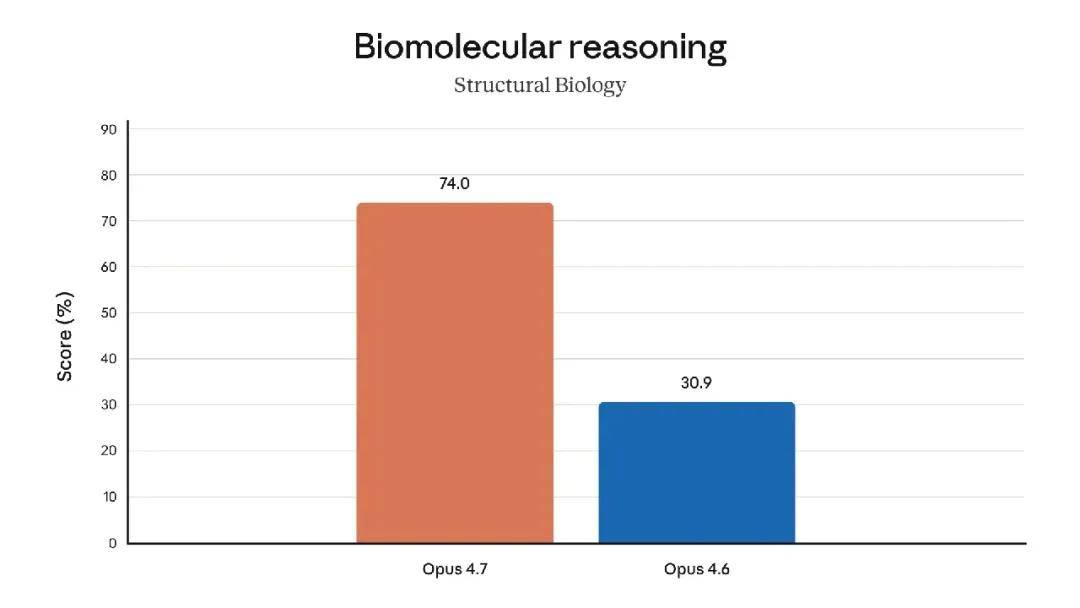
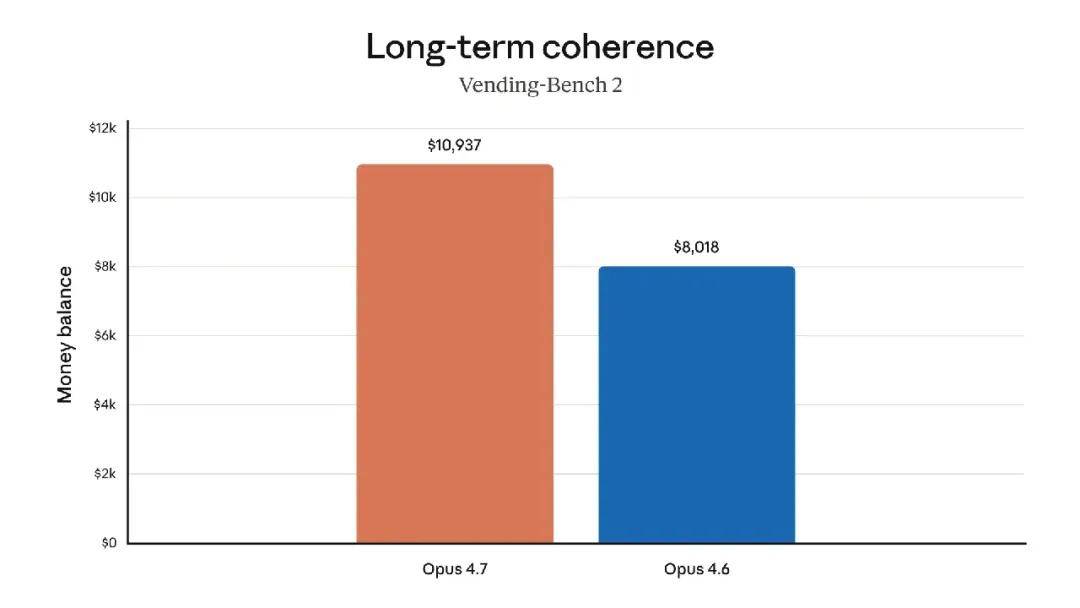
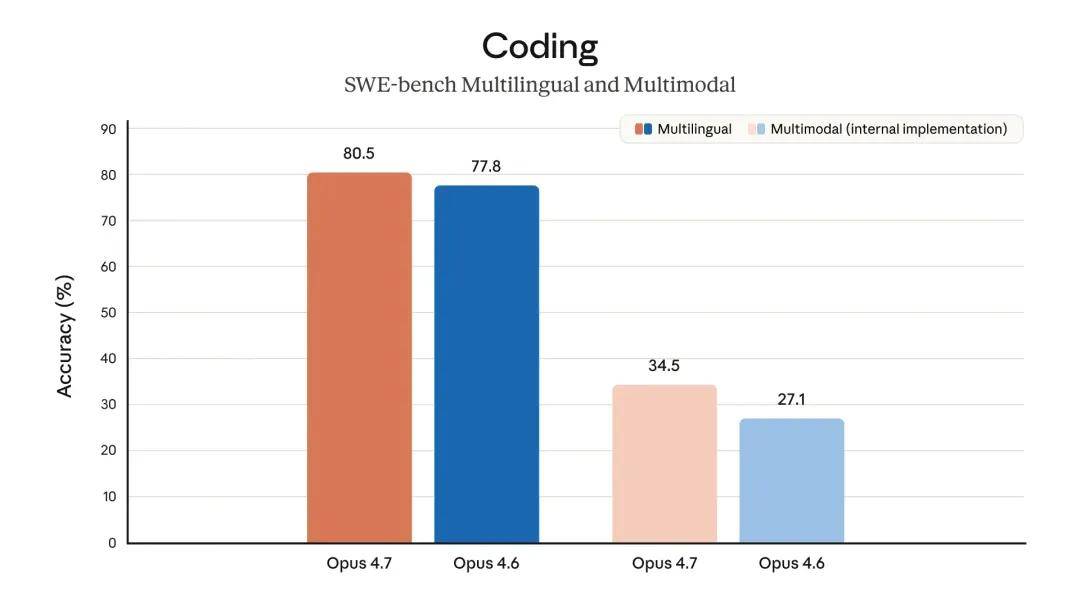
The model also boasts significantly better visual capabilities: it can recognize higher resolution images and demonstrates greater taste and creativity when completing professional tasks, producing higher quality interfaces, slides, and documents. Although its functionality is not as comprehensive as the recently announced strongest model, Claude Mythos Preview, it outperformed Opus 4.6 in several benchmark tests:
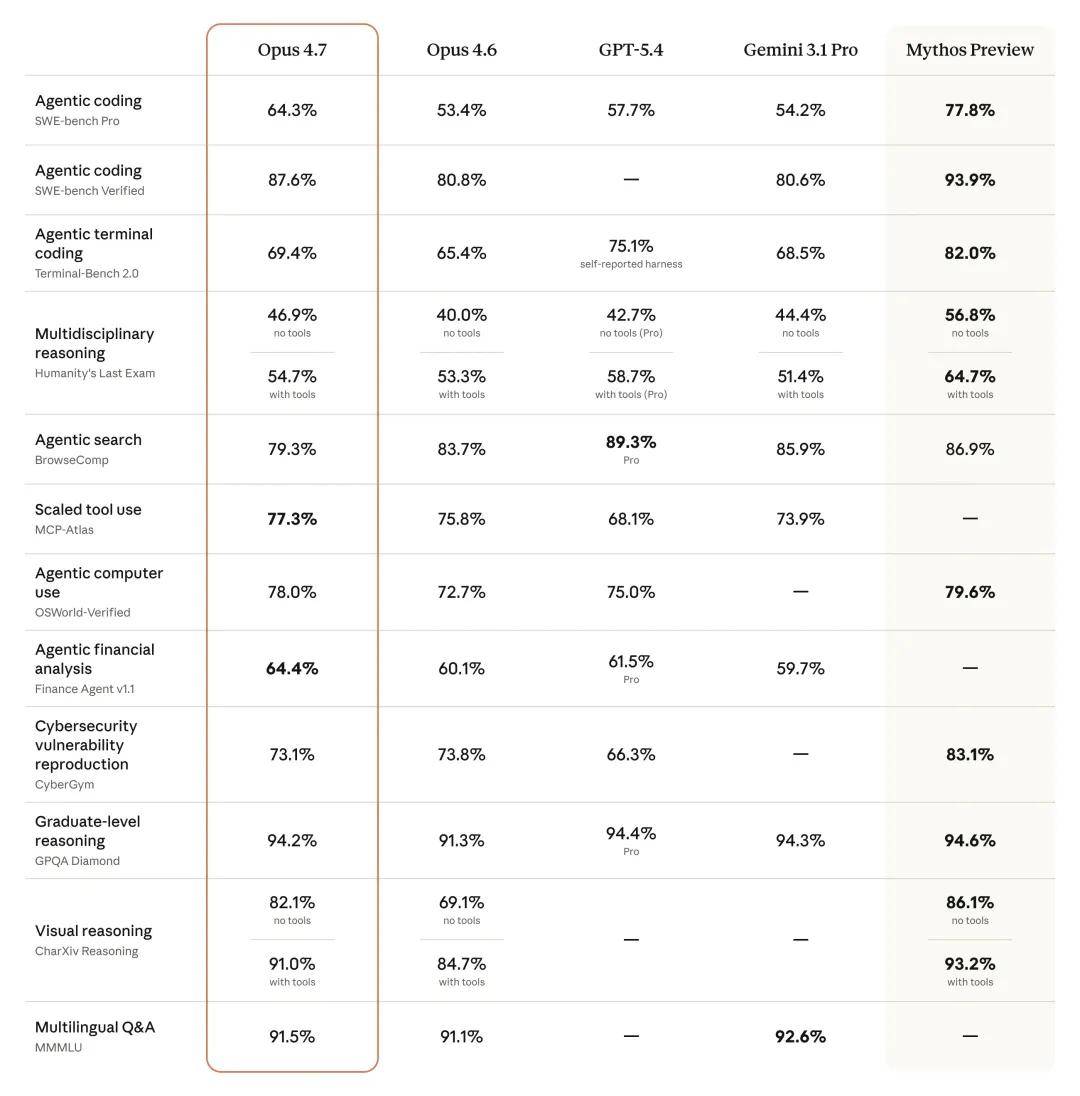
The SWE-bench Pro score reached 64.3%, significantly higher than GPT-5.4’s 57.7%.
Opus 4.7 has been launched across all Claude products and APIs, Amazon Bedrock, Google Cloud’s Vertex AI, and Microsoft Foundry platforms. Pricing remains the same as Opus 4.6: $5 per million input tokens and $25 per million output tokens. Developers can access it via the Claude API.
Current user feedback indicates that the new model is more rigorous, with improved consistency in complex tasks, showing significant progress in the most challenging programming tasks. However, this comes at a cost:
Here are some highlights from the early testing of Opus 4.7:
- Instruction Execution: Opus 4.7 shows a significant improvement in executing instructions. Interestingly, this means that prompts written for previous versions may now yield unexpected results: earlier versions had a broader interpretation of instructions and sometimes skipped parts entirely, while Opus 4.7 strictly follows commands. Users should adjust their prompts and related settings accordingly.
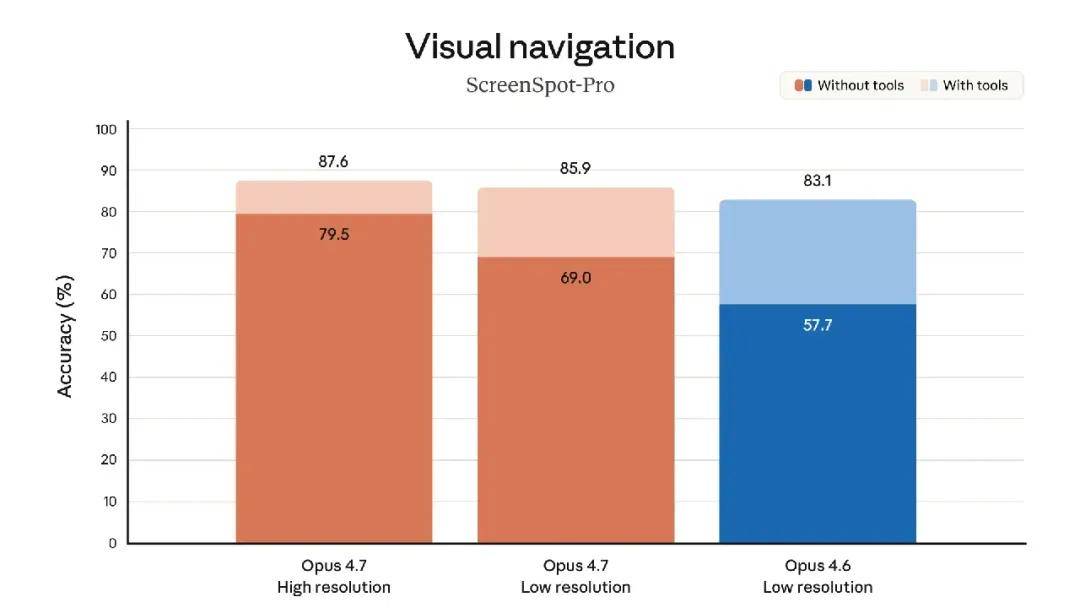
- Improved Multimodal Support: Opus 4.7 has enhanced capabilities for processing high-resolution images: it can handle images with a long edge of up to 2576 pixels (about 3.75 million pixels), more than three times that of previous Claude models. This opens up vast possibilities for multimodal applications that rely on fine visual details: agents can read dense screenshots, extract data from complex charts, and work requiring pixel-level precision.
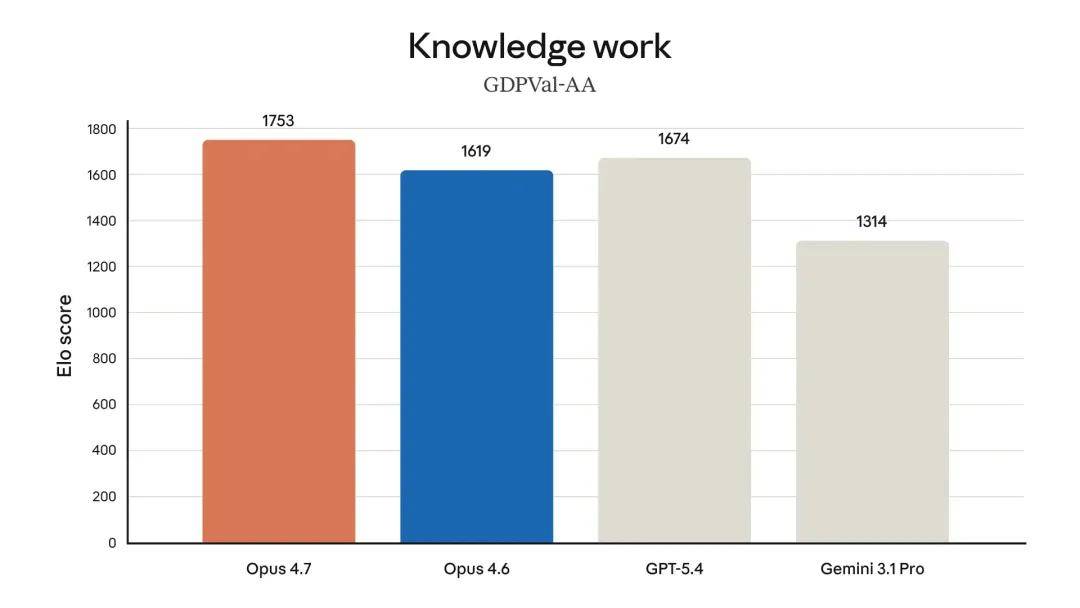
- Enhanced Practical Application: Besides achieving leading levels in financial proxy assessments (see above table), internal tests by Anthropic show that Opus 4.7 performs financial analysis more efficiently than Opus 4.6, generating rigorous analyses and models, presenting more professional presentations, and achieving tighter integration across tasks. Opus 4.7 also leads in GDPval-AA assessments.
- Memory Utilization: Opus 4.7 is better at utilizing filesystem memory. It can remember important notes from long-term, multi-session work and use these notes to continue executing new tasks, thus requiring less prior contextual information for these new tasks.
Boris Cherny, head of Claude Code, introduced some of the latest features of Claude Opus 4.7.
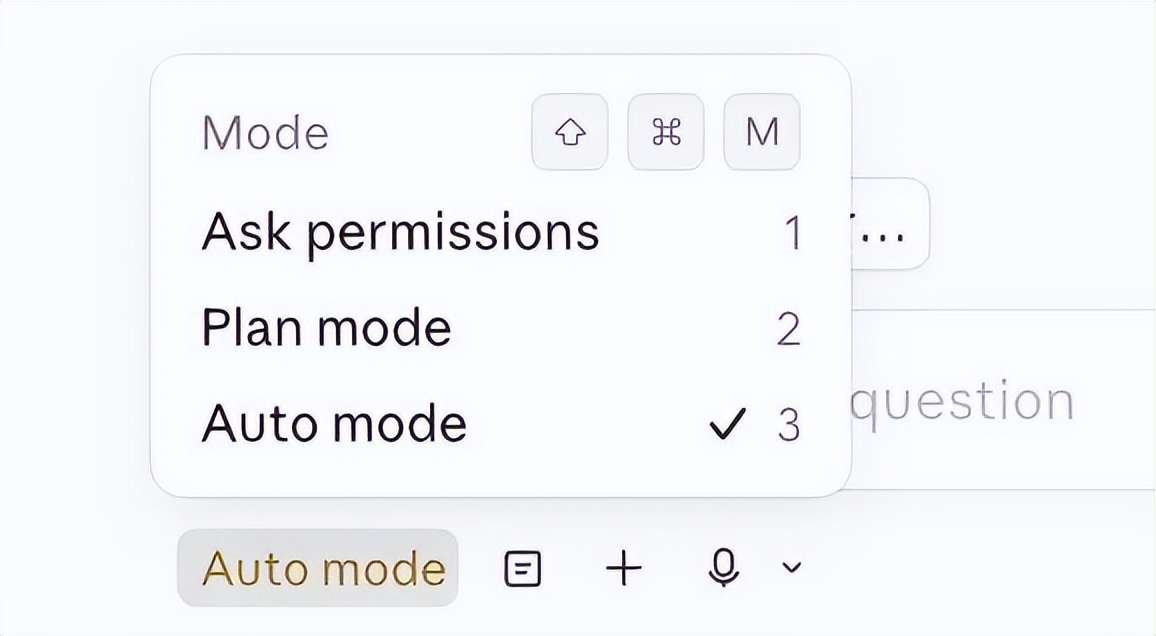
1. Automatic Mode
Opus 4.7 enjoys executing complex, long-running tasks such as deep research, code refactoring, building complex features, and iterating until performance benchmarks are met. In the past, you either had to supervise the model throughout these long tasks or use –dangerously-skip-permissions.
Automatic mode serves as a safer alternative, where permission prompts are routed to a model-based classifier to determine whether the command can be safely executed. If it is safe, it will be automatically approved.
This means that continuous supervision is no longer necessary while the model runs. More importantly, it allows you to run more Claudes in parallel. Once one Claude starts running, you can shift your attention to the next Claude.
2. New /fewer-permission-prompts Skill
This feature scans your session history to identify common bash and MCP commands that are safe and lead to repeated permission prompts. It then recommends a list of commands to add to your permission whitelist.
You can use this feature to optimize your permission settings and avoid unnecessary permission prompts.
3. Review
The review provides a brief summary of what the agent has done and the next steps, which can return to a long-running session after a few minutes or hours.

4. Focus Mode
Focus mode has been added to the CLI, hiding all intermediate steps and focusing solely on the final result. The new model has reached a level where we generally trust it to run the correct commands and make the right edits, only needing to check the final outcome.
You can toggle it using /focus.
5. Adaptive Thinking Depth
Opus 4.7 uses adaptive thinking rather than a thinking budget. To adjust the model’s level of thinking more or less, Anthropic recommends adjusting the effort level.
Using a lower effort level yields faster responses and lower token usage. Higher effort levels provide maximum intelligence and capability.
Boris Cherny stated that most tasks can use xhigh effort levels, while the most difficult tasks should use max effort levels. Max is only applicable to the current session; other effort levels are sticky and will persist in the next session.
/effort is used to set the effort level.

6. Give Claude a Way to Validate Its Work
Finally, ensure Claude has a way to validate its work. This has always been a method to get 2-3 times the output from Claude, and in version 4.7, it is more important than ever.
The validation method varies by task. For backend work, ensure Claude knows how to start your server/service for end-to-end testing; for frontend work, use the Claude Chromium extension to allow Claude to control your browser; for desktop applications, use computer use.
Boris Cherny mentioned that many of his recent prompts look like this: “Claude do blah blah /go”. /go is a skill that allows Claude to 1) perform end-to-end self-testing using bash, a browser, or computer use; 2) run the /simplify skill; 3) submit a PR.
Last week, Anthropic launched the “Project Glasswing” initiative, focusing on the risks and benefits of AI models in cybersecurity. Anthropic announced it would limit the release scope of Claude Mythos Preview and first test new cybersecurity measures on less capable models.
Opus 4.7 is the first of such models: its cybersecurity capabilities are not as strong as Mythos Preview (Anthropic stated that various methods were tried during training to gradually reduce its cybersecurity capabilities). The released Opus 4.7 comes equipped with safety measures that can automatically detect and block requests indicating prohibited or high-risk cybersecurity uses.
Anthropic will gain experience from the practical deployment of these safety measures, ultimately aiming for the broad release of Mythos-level models.
Overall, the security performance of Opus 4.7 is similar to that of Opus 4.6: Anthropic’s assessments show a lower incidence of concerning behaviors such as deception, flattery, and collusion with abusers. In some metrics, such as honesty and resistance to malicious “fast injection” attacks, Opus 4.7 has improved over Opus 4.6; however, in other metrics, such as providing overly detailed harm reduction advice on regulated drugs, Opus 4.7 shows slight shortcomings.
Anthropic’s consistency evaluation concludes that the model “is generally consistent and trustworthy, but its behavior is not entirely ideal.” Notably, according to the evaluation, Mythos Preview remains the most consistent model.
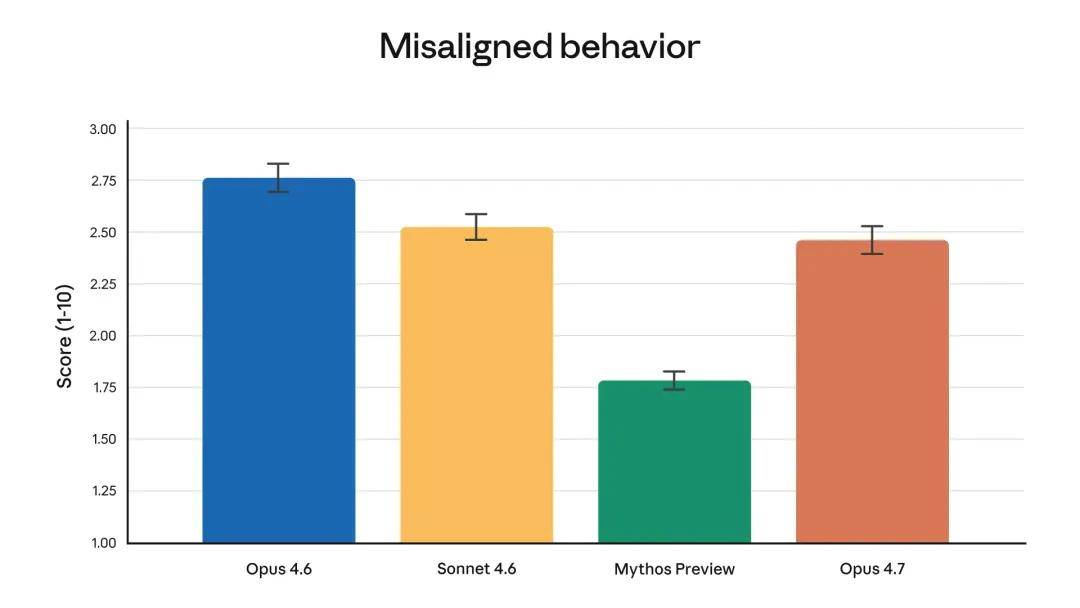
According to automated behavior audits, the overall behavior bias scores are as above.
In addition to Claude Opus 4.7 itself, Anthropic will also roll out the following updates:
Finer difficulty control: Opus 4.7 introduces an xhigh “super high” level between high and max, allowing users to more precisely control the trade-off between reasoning speed and latency when solving difficult problems. In Claude Code, Anthropic has raised the default level for all packages to xhigh. When testing Opus 4.7 in coding and agent application scenarios, it is recommended to start at high or xhigh levels.
On the Claude platform (API): In addition to supporting higher resolution images, Anthropic has launched task budgets in the public beta, enabling developers to guide Claude’s token spending so that it can prioritize work over longer periods.
In Claude Code: The new /ultrareview slash command creates a dedicated review session that reads all changes and highlights errors and design issues that careful reviewers can spot. Anthropic offers three free ultra reviews for Claude Code Pro and Max users for trial. Anthropic has also extended automatic mode to Max users. Automatic mode is a new permission option where Claude makes decisions for you, allowing longer tasks to run with fewer interruptions and a lower risk than humans skipping all permissions.
Opus 4.7 is a direct upgrade from Opus 4.6, but there are two changes worth noting as they affect token usage. First, Opus 4.7 uses an updated tokenizer that improves how the model processes text. Thus, it is believed to likely be a new foundational model, possibly derived from Mythos.
However, the trade-off is that the same input may map to more tokens — approximately increasing by 1.0 to 1.35 times depending on the content type. Secondly, Opus 4.7 will engage in more thinking under high difficulty tasks, especially in later rounds of active voice scenarios. This improves the model’s reliability in solving problems but also means it will generate more output tokens.
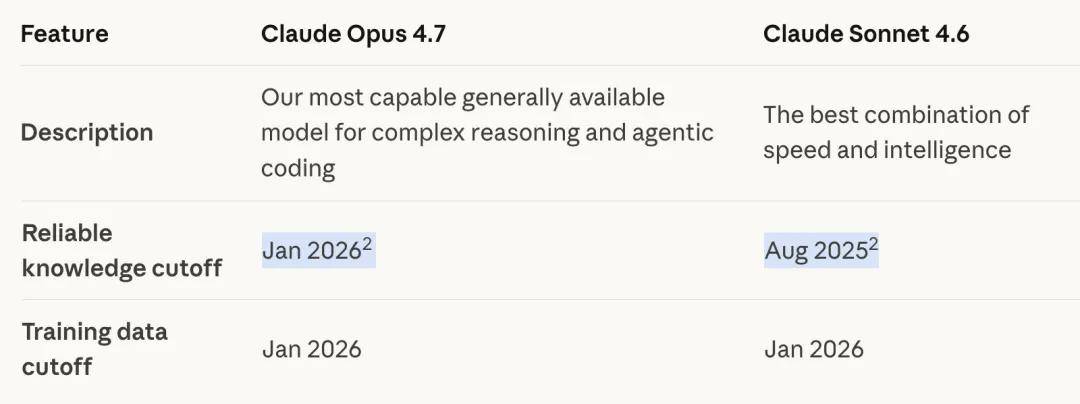
Users have also noted that Opus 4.7’s knowledge cutoff date has been updated:
Users can control token usage in various ways: for example, by using workload parameters, adjusting task budgets, or guiding the model to simplify code. In Anthropic’s own tests, the final results are positive — internal coding evaluations show that token usage rates have improved across all workload levels (as shown below) — but Anthropic recommends evaluating on actual traffic.
Anthropic has also written a migration guide (https://platform.claude.com/docs/en/about-claude/models/migration-guide# migrating-to-claude-opus-4-7) providing more advice on upgrading from Opus 4.6 to Opus 4.7.
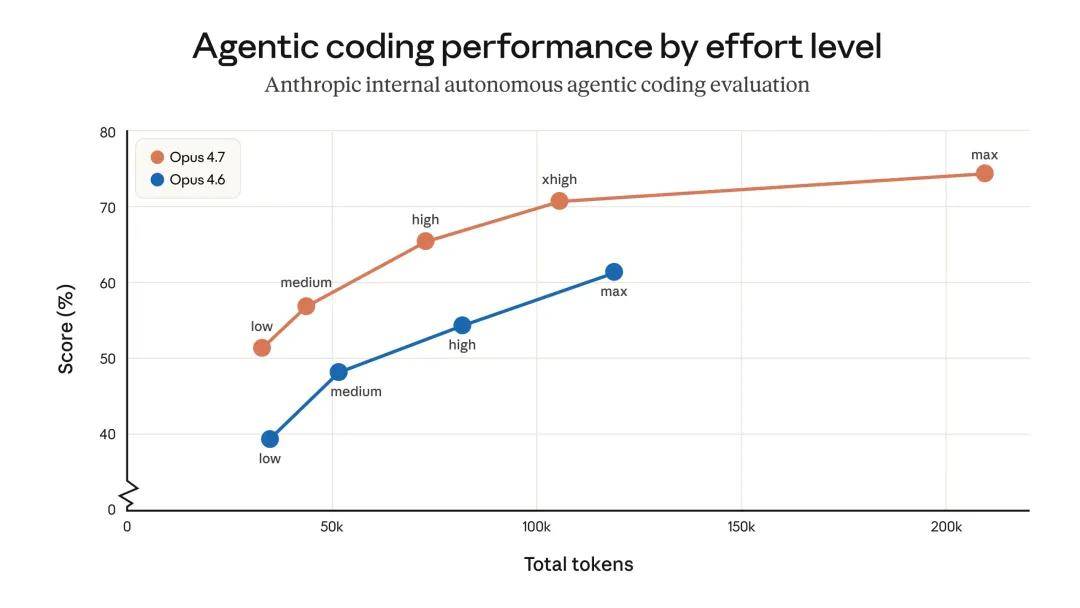
The scoring of internal intelligent coding evaluations by token usage under each workload level. In this evaluation, the model runs autonomously under a single user prompt, so the results may not represent token usage in interactive coding.
After the release of Opus 4.7, large-scale testing and evaluation began, with most users finding the new model performs well, although some noted its token consumption is quite high (pro users running two or three questions quickly exhaust their quota).
Also, just last night, Qwen released Qwen3.6-35B-A3B (35 billion parameters, activating 3 billion), with some reporting that the Qwen model running on their MacBook Pro M5 via LM Studio (and the llm-lmstudio plugin) produced better results for “pelican riding a bicycle” than Opus 4.7.
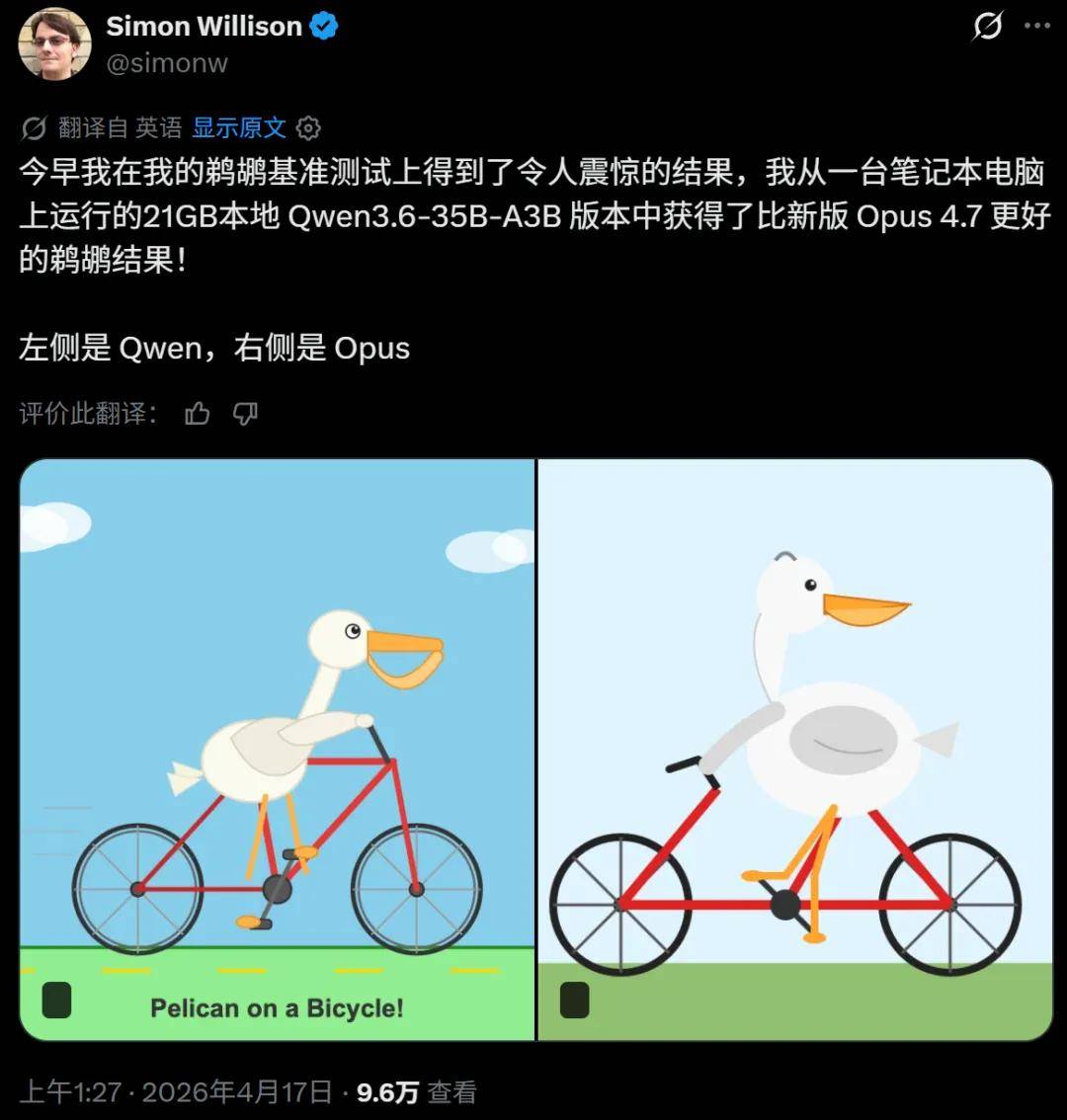
Of course, this does not necessarily mean Qwen3.6-35B-A3B is stronger.
More usage scenarios await further verification.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.